
STL-第四章
所谓序列式容器,其中的元素都可序,但未必有序,C++语言本身提供了一个序列式容器array,STL另外再提供vector、list、deque、stack、queue、priority-queue等序列容器。其中stack和queue由于只是将deque改头换面而成,技术上被归类为一种配接器。
本文将主要总结各种序列式容器的实现和用法。
1、vector容器
vector的数据安排以及操作方式,与array非常相似,两者的唯一差别在于空间的运用的灵活性。array是静态空间,一旦配置就不能改变,如果要换个大点的空间,需要程序员自己来;vector是动态空间,随着元素的加入,它的内部机制会自行扩充空间以容纳新元素。
vector的实现技术,关键在于其对大小的控制以及重新配置时的数据移动效率。因为“配置新空间/数据移动/释放旧空间”是一个大工程。
1.1 vector的迭代器
由于vector使用的是连续线性的空间,普通指针能满足所有vector迭代器的所需的操作行为,所以其迭代器实际就是原生指针,支持随机存取,为Random Access Iterator。
1.2 vector的数据结构
vector所采用的数据结构:线性连续空间。
它以两个迭代器start和finish分别指向配置得来的连续空间中目前已被使用的范围,并以迭代器end_of_storage指向整块连续空间(含备用空间)的尾端。
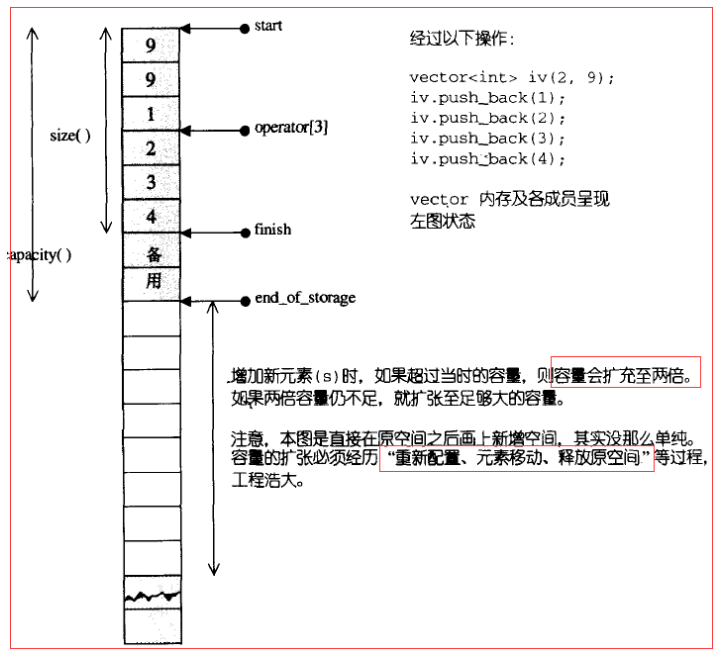
vector的空间配置策略为:
- 当插入元素的时候,如果配置的空间不足,则扩充空间至当前的两倍,如果仍然不足则扩充至所需空间。
- 容量的扩张必须经历“重新配置、元素移动、释放原空间”等过程。
Note:Vector扩容倍数与平台有关,在Win + VS 下是 1.5倍,在 Linux + GCC 下是 2 倍。
测试代码:
1 |
|
运行上述代码,一开始配置了一块长度为2的空间,接下来插入一个数据,长度变为原来的两倍,为4,此时已占用的长度为3,再继续两个数据,此时长度变为8,可以清晰的看到空间的变化过程
需要注意的是,频繁对vector调用push_back()对性能是有影响的,这是因为每插入一个元素,如果空间够用的话还能直接插入,若空间不够用,则需要重新配置空间,移动数据,释放原空间等操作,对程序性能会造成一定的影响。
emplace_back()和push_back()的区别
总结:
1、push_back() 在底层实现时,会优先选择调用移动构造函数,如果没有才会调用拷贝构造函数。
2、push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);而 emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
3、emplace_back不能完全代替push_back。
举例说明:
总结1,2:
1 |
|
运行结果
1 | emplace_back: |
这里将移动构造函数注释掉
1 | emplace_back: |
因此,push_back() 在底层实现时,会优先选择调用移动构造函数,如果没有才会调用拷贝构造函数。
总结3:
https://www.zhihu.com/question/387522517/answer/1151089633
例子1:
1 |
|
我认为不知道你{1,2,3}是什么类型。
例子2:直接构造的坏处
1 | std::vector<std::regex> v; |
例子3:特殊情况只能用push_back
https://www.zhihu.com/question/347743586/answer/835340740
1 | struct S { |
resize()和reserve()的区别
resize用法
- resize(n)
-
调整容器的长度大小,使其能容纳n个元素。
-
如果n小于容器的当前的size,则删除多出来的元素。
-
否则,添加采用值初始化的元素。
- resize(n,t)
- 多一个参数t,将所有新添加的元素初始化为t。
reserve用法
- 预分配n个元素的存储空间。
看个例子
1 |
|
输出结果
1 | 50 100 |
容器的capacity(容量)与size(长度)
(1)capacity:该值在容器初始化时赋值,指的是容器能够容纳的最大的元素的个数。还不能通过下标等访问,
因为此时容器中还没有创建任何对象。
(2)size:指的是此时容器中实际的元素个数。可以通过下标访问0-(size-1)范围内的对象。
补充:
- 关于扩容,MSVC种是以1.5倍扩容;扩容时,将之前元素转移到新内存时存在两种情况,如果移动构造函数为noexcept或者不存在拷贝构造时,执行移动操作;否则执行拷贝动作。
- 关于移除元素:还可以使用倒序移除,
2、list容器
list是一个双list是一个双向链表,每次插入或删除一个元素,就分配或释放一个元素的空间;所以list对空间的控制十分精确,而且任何位置的插入或删除需要的时间都是常数,即时间复杂度为o(1)。
list和vector是两种最常用的容器,什么时候选用哪种容器,视元素的多寡、元素的构造复杂度以及元素存取的行为特性,一般来说查找比较多的情况用vector,而插入和删除比较多的场景则比较适合list。
list节点的结构见如下源码:
1 | template <class T> |
2.1 list的迭代器
list迭代器正确的递增、递减、取值、成员取用操作是指,递增指向下一个节点,递减指向上一个节点,取值取的是节点的数据值,成员取用时取用的是节点的成员。list不能再以原生指针作为迭代器,而需要定义特定的iterator类。list迭代器是一种Bidirectional Iterator,支持单步的前进或后退操作。
list迭代器有一个重要性质:插入和结合操作都不会有list迭代器失效,这在vector是不成立的,因为vector的插入操作可能造成原来的重新配置,导致原有的迭代器全部失效。list的元素删除操作也只有指向删除元素的那个迭代器失效,其他迭代器不受影响。
这是因为 std::list 使用链表实现,插入和删除只需要修改指针。
2.2 list的数据结构
list的结构如下图,SGI list不仅是一个双向链表,而且还是一个环状双向链表,所以它只需一个指针,便可完整表现整个链表。
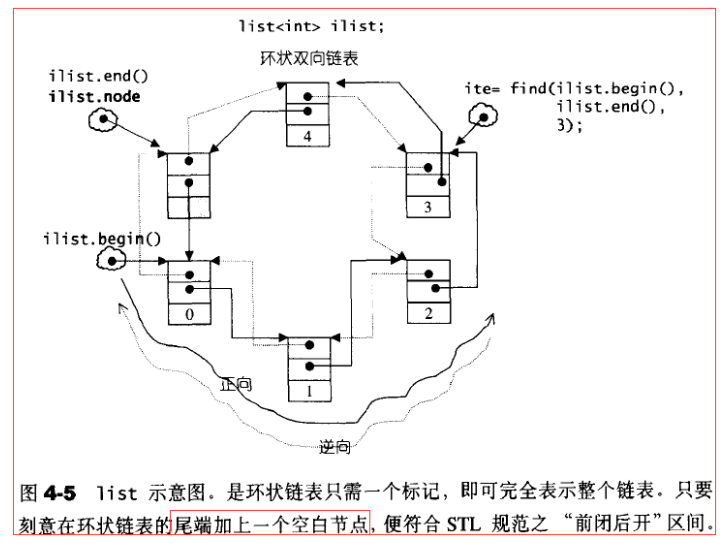
list缺省使用alloc作为空间配置器,以节点大小为配置单位。
当我们以push_back()将元素插入list尾部时,此函数内部调用insert(),insert()是一个重载函数,有多种形式最简单的一种是:首先配置并构造一个节点,然后在尾端进行适当的指针操作,最后将节点插入进去,list不像vector那样有可能在空间不足时做重新配置、数据移动的操作,所以插入前的所有迭代器在插入操作之后都仍然有效。由于list是一个双向循环链表,只要我们把边界条件处理好,那么,在头部或者尾部插入元素的操作几乎是一样的,list内部提供一个所谓的迁移操作:将某连续范围的元素迁移到某个特定位置之前,节点间的指针移动而已。
需要注意的是:list不能使用stl提供的通用sort算法,因为sort算法只接受Random Access Iterator,所以提供了自己的sort方法,可以直接调用,其内部好像是将原链分解为多个链表,然后依次进行合并。
3、deque容器
vector是单向开口的连续线性空间,deque则是一种双向开口的连续线性空间。所谓双向开口,意思是可以在头尾分别做元素的的安插和删除操作;vector当然也可以在头尾两端做动作,但是其头部动作效率奇差。
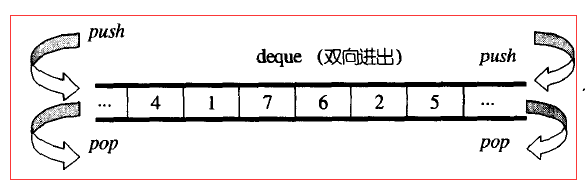
deque和vector的差异:
- 一在于deque允许常数时间内对头端进行元素的插入或移除操作
- 二在于deque没有所谓容量观念,因为它是动态地以分段连续空间组合而成,随时可以增加一段新的空间并链接起来。deque没有必要提供所谓的空间保留功能。vector只能向尾端“生长”,而deque可以在前端或者尾端增加新空间。不存在像vector那样“因空间不足而分配一块更大的空间然后复制元素”问题。
3.1 deque的迭代器
deque提供random access iterator,但并不是原生指针。其实现的复杂度也很大,这也影响到相关算法的效率。所以如非必要,应该尽量使用vector而不是deque。对的确需要进行排序时,可以先将元素复制到一个vector,排序后再复制回deque。
3.2 deque的数据结构
deque的数据结构如下:
1 | class deque |
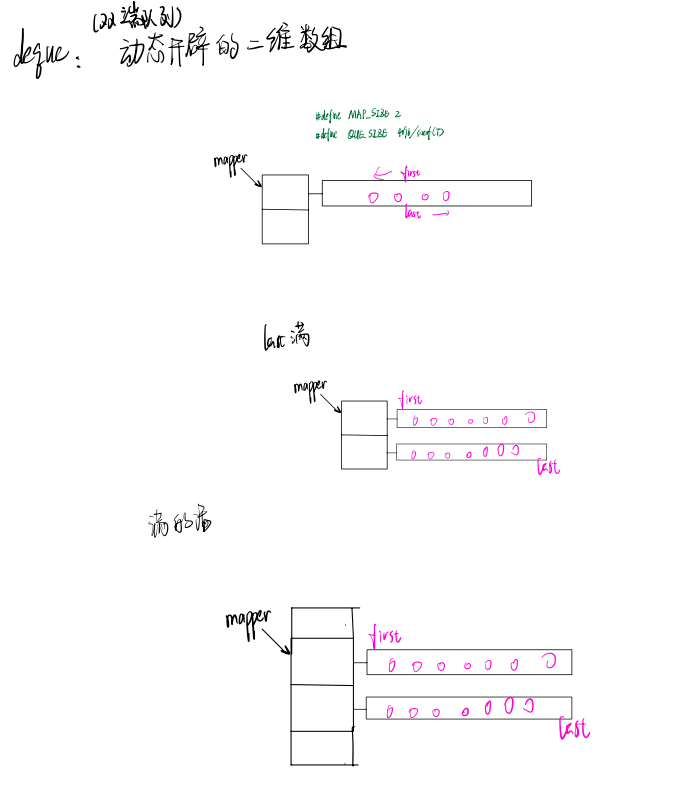
deque采用的是一种分段连续空间存储结构,采用一个map来管理这些空间段,这里所谓map是一小块连续空间,其中每个元素都是指针,指向另外一段较大的连续线性空间,称为缓冲区,缓冲区才是deque的存储空间主体,SGI STL允许我们指定缓冲区大小,默认值0表示使用512bytes缓冲区。
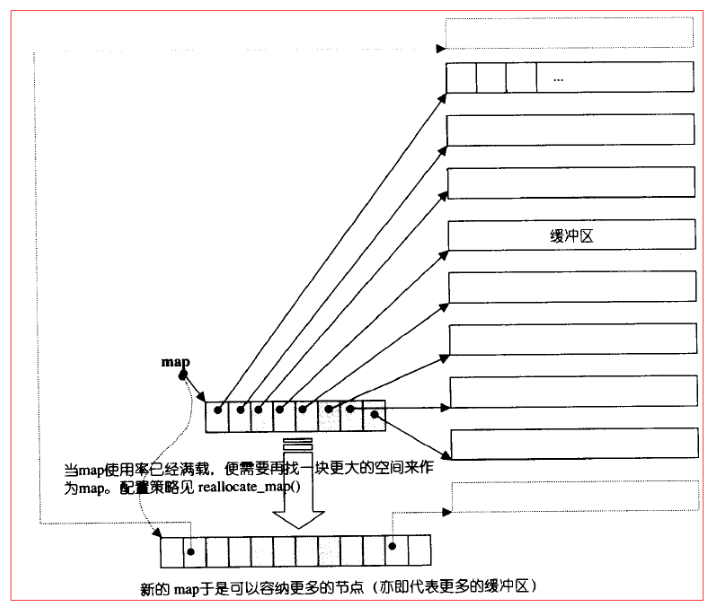
由于每个缓冲区的大小是固定的,当有新元素加入而空间不足时,就分配一个新的缓冲区,配置策略为reallocate_map()。 deque的这种结构,使得其迭代器上的操作可能需要跨越多个缓冲区,这使得迭代器的实现非常复杂。
deque的迭代器数据结构如下:
1 | struct __deque_iterator |
从deque的迭代器数据结构可以看出,为了保持与容器联结,迭代器主要包含上述4个元素
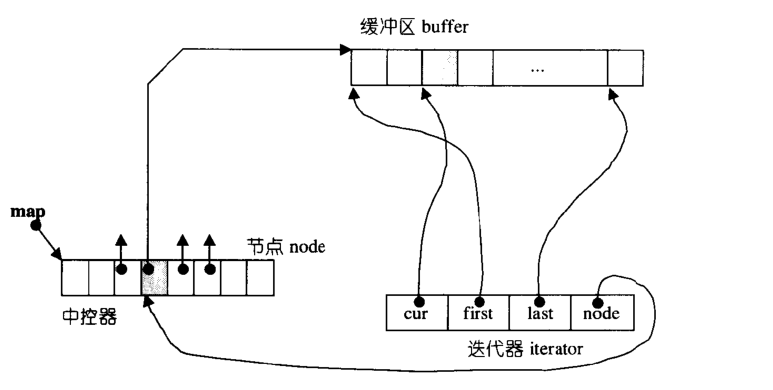
deque迭代器的“++”、“–”操作是远比vector迭代器繁琐,其主要工作在于缓冲区边界,如何从当前缓冲区跳到另一个缓冲区,当然deque内部在插入元素时,如果map中node数量全部使用完,且node指向的缓冲区也没有多余的空间,这时会配置新的map(2倍于当前+2的数量)来容纳更多的node,也就是可以指向更多的缓冲区。在deque删除元素时,也提供了元素的析构和空闲缓冲区空间的释放等机制。
Note:deque 并不是每个缓冲区都对应一个迭代器。deque 只有一个整体的迭代器,它负责在整个 deque 的缓冲区之间进行跳转。

4、stack容器
stack是一种先进后出的数据结构,它只有一个出口,stack允许新增元素、移除元素、取得最顶端元素。但除了最顶端元素外,没有任何其他方式可以存取stack的其他元素,换言之,stack不允许有遍历行为。
stack不支持对元素的遍历,因此没有迭代器。
4.1 stack的数据结构
stack是一种先进后出的数据结构,只可以在顶端进行元素操作。如果有某种双向开口的数据结构,将其接口改变,符合“先进后出”的特性,就可以形成一个stack:deque和list都是这样的结构。
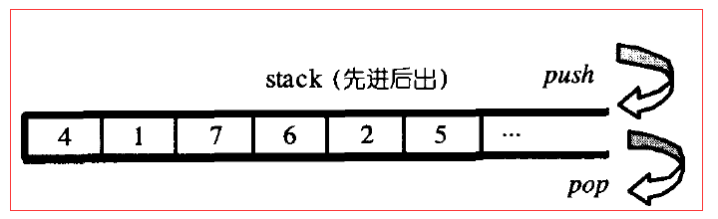
SGI STL便以deque作为缺省情况下的stack底部结构。由于stack是以底部容器deque完成其所有工作,而具有这种“修改某物接口,形成另一种风貌”之性质者,称为adapter(配接器),因此,STL stack往往不被归类为container(容器),而被归类为container adapter。
5、queue容器
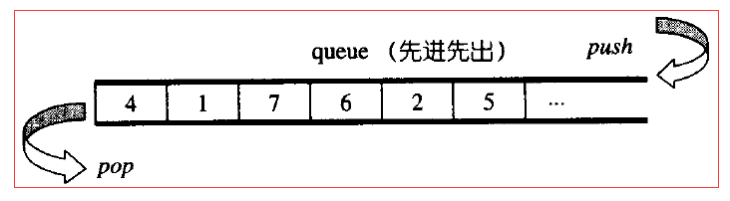
queue是一种先进先出的数据结构,它有两个出口。queue允许新增元素、移除元素、从底端加入元素、取得最顶端元素(queue不允许有遍历行为)。
与stack一样,queue也不允许有遍历行为,queue没有迭代器。
与stack类似,SGI STL默认情况下以deque作为queue的底部结构。也是一种container adapter。
6、heap
heap并不归属于STL容器组件,它是个幕后英雄,扮演priority queue的助手,它分为 max heap 和min heap,在缺省情况下,max-heap是priority queue的底层实现机制。
6.1 heap的数据结构
以array表达tree的方式,称为隐式表述法,这样就可以使用一个array表示出一颗完全二叉树。array的缺点是无法动态的改变大小,所以实际实现机制中的max-heap实际上是以一个vector表现的完全二叉树。
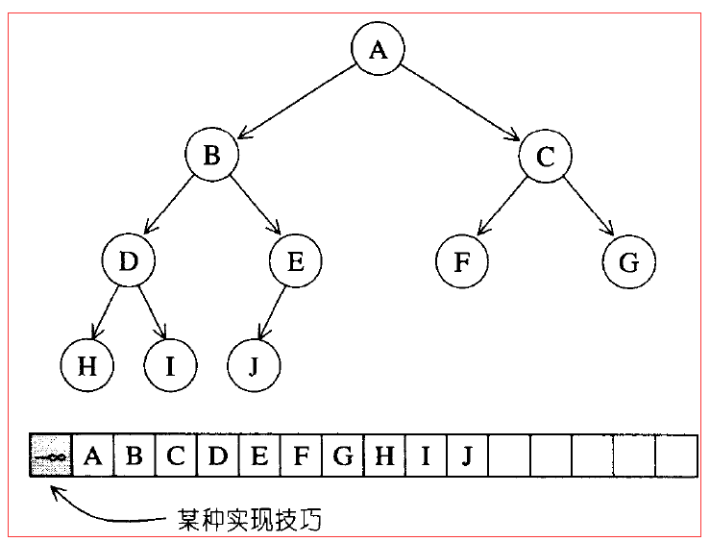
从上图可以看出,第0号元素保留,这样就可以使得从arry[1]开始保存A,位于位置i的某个结点arry[i],他的左子结点必然在arry[2i]中,右子结点必然位于arry[2i+1],其父亲结点必然位于arry[i/2]处。
6.2 heap的相关算法
- (1)建立堆:make_heap(_First, _Last, _Comp)
传入vector的迭代器,默认是建立最大堆的。对int类型,可以在第三个参数传入greater()得到最小堆。 - (2)在堆中添加数据:push_heap(_First, _Last)
要先在容器中加入数据push_back(),再调用push_heap(),vector的元素放在尾端,所以实际上push_heap所做的操作就是将尾端元素和其父节点进行比较,如果大于父节点则交换并不断上溯直到不满足大于为止。 - (3)在堆中删除数据:pop_heap(_First, _Last)
该算法主要是先将vector的根节点即最大值放到vector的尾端,然后处理[start,end-1)区间的元素,从根节点开始,只要父节点的元素小于某个子节点的元素就进行交换并继续下溯,否则停止。 调用pop_heap()结束后vector()可以通过pop_back()取出最大元素。 - (4)堆排序sort_heap(_First, _Last)
sort_heap算法的内部实现原理:每次pop_heap可获得heap中键值最大的元素,如果持续对整个heap做pop_heap操作,每次将操作范围从后向前缩减一个元素,当整个程序执行完毕时,便有了一个递增的序列。
6.3 heap的迭代器
heap本身并不是一个容器,它更多的是依靠vector容器底层,并在上面实现算法从而实现对tree的表达。heap不提供遍历功能,也没有对应的迭代器。
7、priority__queue
priority_queue是一个拥有权值观念的queue,它允许加入新元素、移除旧元素、审视新元素等功能。由于是一个queue,所以只能在底端加入元素,在顶端取出元素。
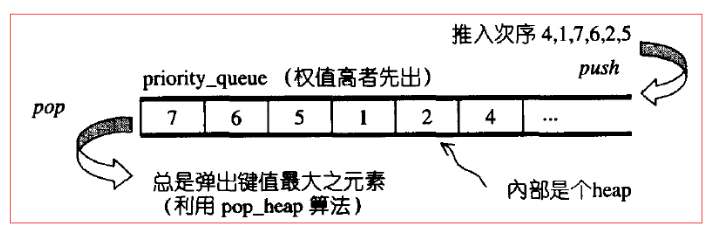
priority_queue带有权值概念,其内的元素并非依照被推入的次序排列,而是自动依照元素的权值排列。priority_queue缺省情况下是以vector为底层容器,并加上heap处理规则实现,因此,STL priority_queue往往不被归类为container(容器),而被归类为container adapter。
与queue一样,priority_queue也没有迭代器。
8、slist
list是双向链表,而slist(single linked list)是单向链表,它们的主要区别在于:前者的迭代器是双向的Bidirectional iterator,后者的迭代器属于单向的Forward iterator。虽然slist的很多功能不如list灵活,但是其所耗用的空间更小,操作更快。
根据STL的习惯,插入操作会将新元素插入到指定位置之前,而非之后,然而slist是不能回头的,只能往后走,因此在slist的其他位置插入或者移除元素是十分不明智的,但是在slist开头却是可取的,slist特别提供了insert_after()和erase_after供灵活应用。
考虑到效率问题,slist只提供push_front()操作,元素插入到slist后,存储的次序和输入的次序是相反的.
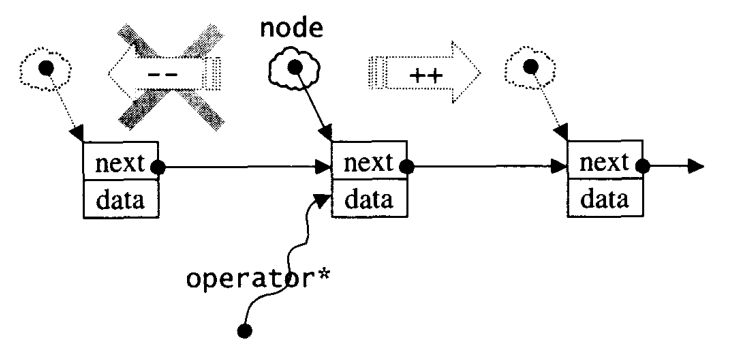
slist的单向迭代器如下图所示:
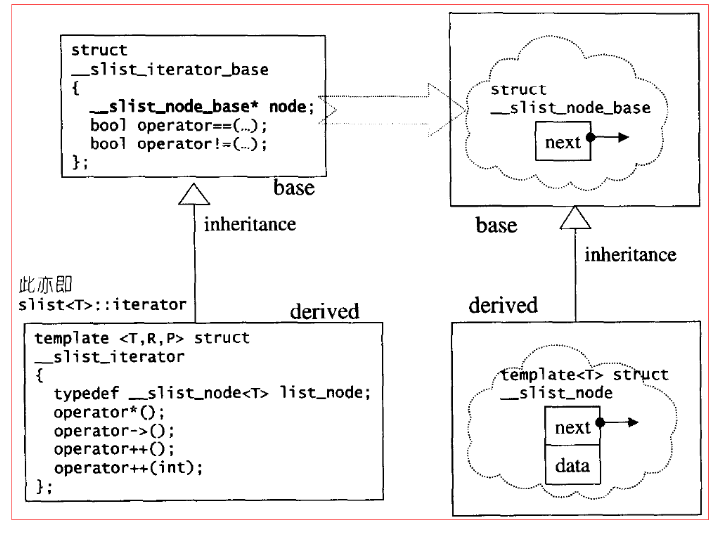
slist默认采用alloc空间配置器配置节点的空间,其数据结构主要代码如下
1 | template <class T, class Allco = alloc> |
举个例子:
1 |
|
9、总结
在实际使用过程中,到底选择这几种容器中的哪一个?通常应该根据遵循以下原则:
(1)如果需要高效的随机存取,不在乎插入和删除的效率,使用vector;
(2)如果需要大量的插入和删除元素,不关心随机存取的效率,使用list;
(3)如果需要随机存取,并且关心两端数据的插入和删除效率,使用deque;
(4)如果打算存储数据字典,并且要求方便地根据key找到value,一对一的情况使用map,一对多的情况使用multimap;
(5)如果打算查找一个元素是否存在于某集合中,唯一存在的情况使用set,不唯一存在的情况使用multiset。




