
Cpp异常机制
不到最后一刻,never give up!!!
C++异常机制概述
异常处理是C++ 的一项语言机制,用于在程序中处理异常事件。异常事件在C++中表示为异常对象。异常事件发生时,程序使用throw关键字抛出异常表达式,抛出点称为异常出现点,由操作系统为程序设置当前异常对象,然后执行程序的当前异常处理代码块,在包含了异常出现点的最内层的try块,依次匹配catch语句中的异常对象(只进行类型匹配,catch参数有时在catch语句中并不会使用到)。若匹配成功,则执行catch块内的异常处理语句,然后接着执行try…catch…块之后的代码。如果在当前的try…catch…块内找不到匹配该异常对象的catch语句,则由更外层的try…catch…块来处理该异常;如果当前函数内所有的try…catch…块都不能匹配该异常,则递归回退到调用栈的上一层去处理该异常。如果一直退到主函数main()都不能处理该异常,则调用系统函数terminate()终止程序。
一个最简单的try…catch…的例子如下所示。我们有个程序用来记班级学生考试成绩,考试成绩分数的范围在0-100之间,不在此范围内视为数据异常:
1 | int main() |
throw 关键字
在上面这个示例中,throw是个关键字,与抛出表达式构成了throw语句。其语法为:
1 | throw 表达式; |
throw语句必须包含在try块中,也可以是被包含在调用栈的外层函数的try块中,如:
1 | //示例代码:throw包含在外层函数的try块中 |
执行throw语句时,==throw表达式将作为对象被复制构造为一个新的对象,称为异常对象==。异常对象放在内存的特殊位置,该位置既不是栈也不是堆,在window上是放在线程信息块TIB中。这个构造出来的新对象与本级的try所对应的catch语句进行类型匹配,类型匹配的原则在下面介绍.
补充:
在Linux下,异常对象被存放在一个特殊的内存区域,这个内存区域被称为异常处理堆(Exception Handling Heap)。这个堆是由操作系统提供的,它不同于程序员常说的堆(即通过new、malloc等函数进行动态分配的堆),也不同于栈(即函数调用时用来存储局部变量和函数调用信息的栈)。
当一个异常被抛出时,异常对象会被复制构造到这个异常处理堆上。这个异常对象会在整个异常处理过程中保持其生命周期,直到异常被完全处理并恢复程序的正常执行流程,这时异常对象才会被销毁。
这样设计的原因是,异常处理涉及到栈的展开,也就是局部变量的销毁。如果异常对象存储在栈上,那么在异常处理过程中,异常对象可能会被销毁,这显然是不合理的。所以,异常对象被存储在一个独立的、由操作系统提供的异常处理堆上。
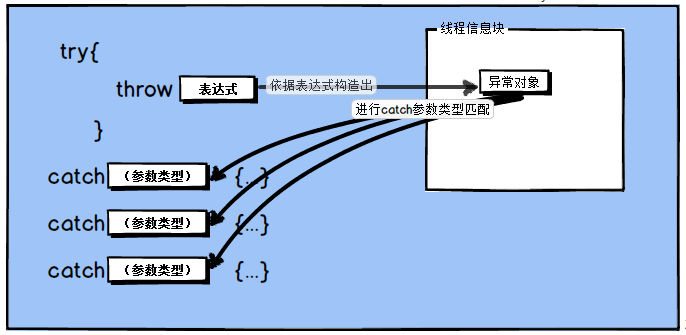
在本例中,依据score构造出来的对象类型为int,与catch(int score)匹配上,程序控制权转交到catch的语句块,进行异常处理代码的执行。如果在本函数内与catch语句的类型匹配不成功,则在调用栈的外层函数继续匹配,如此递归执行直到匹配上catch语句,或者直到main函数都没匹配上而调用系统函数terminate()终止程序。 当执行一个throw语句时,跟在throw语句之后的语句将不再被执行,throw语句的语法有点类似于return,因此导致在调用栈上的函数可能提早退出。
思考:throw和try…catch的区别
try-catch 和 throw 是 C++ 异常处理机制中的两个核心概念,它们的作用和用途不同。
1. try-catch 的作用
try-catch 语句块用于捕获和处理在 try 块中抛出的异常。其主要目的是捕获可能发生的异常,防止程序因未处理的异常而崩溃,并提供相应的错误处理逻辑。
1 |
|
在上面的例子中:
try块包含可能抛出异常的代码。catch块用于捕获异常,并进行相应的处理。
2. throw 的作用
throw 关键字用于显式抛出异常。当程序遇到无法继续执行的错误情况时,可以使用 throw 将异常抛出,使得异常被传递到调用者(或更高层的调用者),直到它被 try-catch 捕获。
1 |
|
在上面的例子中:
divide函数使用throw抛出一个std::runtime_error异常,表示无法执行除法操作。- 在
main函数中,这个异常被try-catch捕获并处理。
总结
throw:用于在程序中显式抛出异常,以通知调用者或更高层的代码出现了错误。try-catch:用于捕获在try块中抛出的异常,并在catch块中对异常进行处理。
异常对象
异常对象是一种特殊的对象,编译器依据异常抛出表达式复制构造异常对象,这要求抛出异常表达式不能是一个不完全类型(一个类型在声明之后定义之前为一个不完全类型。不完全类型意味着该类型没有完整的数据与操作描述),而且可以进行复制构造,这就要求异常抛出表达式的复制构造函数(或移动构造函数)、析构函数不能是私有的。【因为要复制构造异常对象以及catch之后析构对象,因此不应该将其设置为private】
异常对象不同于函数的局部对象,局部对象在函数调用结束后就被自动销毁,而异常对象将驻留在所有可能被激活的catch语句都能访问到的内存空间中,也即上文所说的TIB。当异常对象与catch语句成功匹配上后,在该catch语句的结束处被自动析构。
在函数中返回局部变量的引用或指针几乎肯定会造成错误,同样的道理,在throw语句中抛出局部变量的指针或引用也几乎是错误的行为。如果指针所指向的变量在执行catch语句时已经被销毁,对指针进行解引用将发生意想不到的后果。
throw出一个表达式时,该表达式的静态编译类型将决定异常对象的类型。所以当throw出的是基类指针的解引用,而该指针所指向的实际对象是派生类对象,此时将发生派生类对象切割。
来看个例子解释下:
在C++中,如果你抛出一个基类的引用或者指针,但它实际上指向一个派生类对象,那么在抛出异常时,只有基类部分会被抛出,派生类的部分会被切割掉。这就是所谓的"对象切割"问题。
1 |
|
说明:在这个例子中,Derived是Base的派生类。foo函数接收一个Base的引用,并抛出这个引用。在main函数中,我们创建了一个Derived对象d,并将它作为Base的引用传递给foo函数。当foo函数抛出这个引用时,只有Base部分被抛出,Derived部分被切割掉。所以,当我们在catch块中捕获这个异常并调用print函数时,输出的是"Base",而不是"Derived"。
除了抛出用户自定义的类型外,C++标准库定义了一组类,用户报告标准库函数遇到的问题。这些标准库异常类只定义了几种运算,包括创建或拷贝异常类型对象,以及为异常类型的对象赋值。
| 标准异常类 | 描述 | 头文件 |
|---|---|---|
| exception | 最通用的异常类,只报告异常的发生而不提供任何额外的信息 | exception |
| runtime_error | 只有在运行时才能检测出的错误 | stdexcept |
| rang_error | 运行时错误:产生了超出有意义值域范围的结果 | stdexcept |
| overflow_error | 运行时错误:计算上溢 | stdexcept |
| underflow_error | 运行时错误:计算下溢 | stdexcept |
| logic_error | 程序逻辑错误 | stdexcept |
| domain_error | 逻辑错误:参数对应的结果值不存在 | stdexcept |
| invalid_argument | 逻辑错误:无效参数 | stdexcept |
| length_error | 逻辑错误:试图创建一个超出该类型最大长度的对象 | stdexcept |
| out_of_range | 逻辑错误:使用一个超出有效范围的值 | stdexcept |
| bad_alloc | 内存动态分配错误 | new |
| bad_cast | dynamic_cast类型转换出错 | type_info |
catch 关键字
catch语句匹配被抛出的异常对象。如果catch语句的参数是引用类型,则该参数可直接作用于异常对象,即参数的改变也会改变异常对象,==而且在catch中重新抛出异常时会继续传递这种改变==。如果catch参数是传值的,则复制构函数将依据异常对象来构造catch参数对象。在该catch语句结束的时候,先析构catch参数对象,然后再析构异常对象。
在进行异常对象的匹配时,编译器不会做任何的隐式类型转换或类型提升。
除了以下几种情况外,异常对象的类型必须与catch语句的声明类型完全匹配:
- 允许从非常量到常量的类型转换。
- 允许派生类到基类的类型转换。
- 数组被转换成指向数组(元素)类型的指针。
- 函数被转换成指向函数类型的指针。
寻找catch语句的过程中,匹配上的未必是类型完全匹配那项,而在是最靠前的第一个匹配上的catch语句(我称它为最先匹配原则)。所以,派生类的处理代码catch语句应该放在基类的处理catch语句之前,否则先匹配上的总是参数类型为基类的catch语句,而能够精确匹配的catch语句却不能够被匹配上。
解释:
在查找适合的catch块以处理抛出的异常时,C++会按照代码的顺序从上到下查找,当找到第一个能够匹配抛出的异常类型的catch块时,就会执行这个catch块。如果派生类的catch块被放在了基类的catch块之后,那么基类的catch块就会先被匹配上,派生类的catch块就无法被执行了。
1 |
|
在这个例子中,foo函数抛出了一个Derived类型的异常,但是在main函数中,先匹配上的是Base类型的catch块,所以输出的是"Caught Base"。尽管有一个精确匹配Derived类型的catch块,但是由于它被放在了Base类型的catch块之后,所以它永远不会被执行。
为了避免这种情况,我们应该将派生类的catch块放在基类的catch块之前,就像这样:
1 | int main() { |
这样,当foo函数抛出一个Derived类型的异常时,就会先匹配上Derived类型的catch块,输出的就是"Caught Derived"了。
在catch块中,如果在当前函数内无法解决异常,可以继续向外层抛出异常,让外层catch异常处理块接着处理。此时可以使用不带表达式的throw语句将捕获的异常重新抛出:
1 | catch(type x) |
被重新抛出的异常对象为保存在TIB中的那个异常对象,与catch的参数对象没有关系,若catch参数对象是引用类型,可能在catch语句内已经对异常对象进行了修改,那么重新抛出的是修改后的异常对象;若catch参数对象是非引用类型,则重新抛出的异常对象并没有受到修改。
使用catch(...){}可以捕获所有类型的异常,根据最先匹配原则,catch(...){}应该放在所有catch语句的最后面,否则无法让其他可以精确匹配的catch语句得到匹配。通常在catch(…){}语句中执行当前可以做的处理,然后再重新抛出异常。注意,catch中重新抛出的异常只能被外层的catch语句捕获。
栈展开、RAII
其实栈展开已经在前面说过,就是从异常抛出点一路向外层函数寻找匹配的catch语句的过程,寻找结束于某个匹配的catch语句或标准库函数terminate。这里重点要说的是栈展开过程中对局部变量的销毁问题。我们知道,在函数调用结束时,函数的局部变量会被系统自动销毁,类似的,throw可能会导致调用链上的语句块提前退出,此时,语句块中的局部变量将按照构成生成顺序的逆序,依次调用析构函数进行对象的销毁。例如下面这个例子:
1 | //一个没有任何意义的类 |
程序将输出:
1 | A默认构造函数 |
定义变量a时调用了默认构造函数,使用a初始化异常变量时调用了复制构造函数,使用异常变量复制构造catch参数对象时同样调用了复制构造函数。三个构造对应三个析构,也即try语句块中局部变量a自动被析构了。然而,如果a是在自由存储区上分配的内存时:
1 | int main() |
程序运行结果:
1 | A默认构造函数 |
同样的三次构造,却只调用了两次的析构函数!说明a的内存在发生异常时并没有被释放掉,发生了内存泄漏。 ==RAII机制有助于解决这个问题==,RAII(Resource acquisition is initialization,资源获取即初始化)。它的思想是以对象管理资源。为了更为方便、鲁棒地释放已获取的资源,避免资源死锁,一个办法是把资源数据用对象封装起来。程序发生异常,执行栈展开时,封装了资源的对象会被自动调用其析构函数以释放资源。C++ 中的智能指针便符合RAII。关于这个问题详细可以看《Effective C++》条款13.
条款13:以对象管理资源
为了防止资源泄漏,请使用RAII(Resource Acquisition Is Initialization)对象,在构造函数里面获得资源,在析构函数里面释放资源 auto_ptr(c++11废弃,原因见笔记),shared_ptr,unique_lock都是RAII类。
异常机制与构造函数
异常机制的一个合理的使用是在构造函数中。构造函数没有返回值,所以应该使用异常机制来报告发生的问题。更重要的是,构造函数抛出异常表明构造函数还没有执行完,其对应的析构函数不会自动被调用,因此析构函数应该先析构所有所有已初始化的基对象,成员对象,再抛出异常。 C++类构造函数初始化列表的异常机制,称为function-try block。一般形式为:
1 | myClass::myClass(type1 pa1) |
构造函数抛出异常表明构造函数还没有执行完,其对应的析构函数不会自动被调用.可能会存在内存泄漏。因此提出构造函数初始化列表的异常机制。
1 |
|
异常机制与析构函数
C++不禁止析构函数向外界抛出异常,==但析构函数被期望不向外界函数抛出异常==。析构函数中向函数外抛出异常,将直接调用terminator()系统函数终止程序。如果一个析构函数内部抛出了异常,就应该在析构函数的内部捕获并处理该异常,不能让异常被抛出析构函数之外。可以如此处理:
- 若析构函数抛出异常,调用std::abort()来终止程序。
- 在析构函数中catch捕获异常并作处理。
关于具体细节,有兴趣可以看《Effective C++》条款08:别让异常逃离析构函数。
解释
在C++中,析构函数是不应该抛出异常的。如果析构函数中抛出了异常,那么当对象被销毁,或者在异常处理过程中,对象被销毁时,如果析构函数再次抛出异常,程序就会调用std::terminate函数,导致程序立即崩溃。
这是因为在C++中,如果一个异常没有被捕获,那么程序就会调用std::terminate函数,结束程序的运行。而在一个异常处理过程中,如果又抛出了新的异常,那么这个新的异常就无法被捕获,因为异常处理机制已经在处理一个异常了。
此外,如果析构函数在执行过程中抛出异常并且没有被正确处理,那么对象可能无法被完全销毁,这就可能导致内存泄漏。
所以,为了避免这种情况,我们通常推荐在析构函数中使用try/catch块来捕获并处理可能的异常,或者设计析构函数使其不会抛出异常。如果必须在析构函数中执行可能会抛出异常的操作,那么应该将这些操作放在一个单独的函数中,而不是直接放在析构函数中。
noexcept修饰符与noexcept操作符
noexcept修饰符是C++ 11新提供的异常说明符,用于声明一个函数不会抛出异常。编译器能够针对不抛出异常的函数进行优化,另一个显而易见的好处是你明确了某个函数不会抛出异常,别人调用你的函数时就知道不用针对这个函数进行异常捕获。在C++98中关于异常处理的程序中你可能会看到这样的代码:
1 | void func() throw(int ,double ) {...} |
这是throw作为函数异常说明,前者表示func()这个函数可能会抛出int或double类型的异常,后者表示func()函数不会抛出异常。事实上前者很少被使用,在C++ 11这种做法已经被摒弃,而后者则被C++11的noexcept异常声明所代替:
1 | void func() noexcept {...} |
在C++11中,编译器并不会在编译期检查函数的noexcept声明,因此,被声明为noexcept的函数若携带异常抛出语句还是可以通过编译的。在函数运行时若抛出了异常,编译器可以选择直接调用terminate()函数来终结程序的运行,因此,noexcept的一个作用是阻止异常的传播,提高安全性.
上面一点提到了,我们不能让异常逃出析构函数,因为那将导致程序的不明确行为或直接终止程序。实际上出于安全的考虑,C++ 11标准中让类的析构函数默认也是noexcept的。 同样是为了安全性的考虑,经常被析构函数用于释放资源的delete函数,C++11也默认将其设置为noexcept。
noexcept也可以接受一个常量表达式作为参数,例如:
1 | void func() noexcept(常量表达式); |
常量表达式的结果会被转换成bool类型,noexcept(bool)表示函数不会抛出异常,noexcept(false)则表示函数有可能会抛出异常。故若你想更改析构函数默认的noexcept声明,可以显式地加上noexcept(false)声明,但这并不会带给你什么好处。
【异常后果自负】
在函数运行时若抛出了异常,编译器可以选择直接调用terminate()函数来终结程序的运行,因此,noexcept的一个作用是阻止异常的传播,提高安全性.
异常处理的性能分析
异常处理机制的主要环节是运行期类型检查。当抛出一个异常时,必须确定异常是不是从try块中抛出。异常处理机制为了完善异常和它的处理器之间的匹配,需要存储每个异常对象的类型信息以及catch语句的额外信息。由于异常对象可以是任何类型(如用户自定义类型),并且也可以是多态的,获取其动态类型必须要使用运行时类型检查(RTTI),此外还需要运行期代码信息和关于每个函数的结构。
当异常抛出点所在函数无法解决异常时,异常对象沿着调用链被传递出去,程序的控制权也发生了转移。转移的过程中为了将异常对象的信息携带到程序执行处(如对异常对象的复制构造或者catch参数的析构),在时间和空间上都要付出一定的代价,本身也有不安全性,特别是异常对象是个复杂的类的时候。
异常处理技术在不同平台以及编译器下的实现方式都不同,但都会给程序增加额外的负担,当异常处理被关闭时,额外的数据结构、查找表、一些附加的代码都不会被生成,正是因为如此,对于明确不抛出异常的函数,我们需要使用noexcept进行声明。
问题
Q1:哪些异常要捕获,哪些不用
在 C++ 中,异常处理用于捕获程序运行时发生的异常情况,但并不是所有的异常都需要捕获。以下是哪些异常需要捕获、哪些不需要捕获的详细说明,并附带示例。
- 需要捕获的异常
示例 1: 内存分配失败 (std::bad_alloc)
当内存分配失败时,new 操作符会抛出 std::bad_alloc 异常。对于需要确保程序能够继续运行或采取补救措施的场景,这种异常通常需要捕获。
1 |
|
需要捕获的原因:内存分配失败是可能发生的运行时错误,尤其在内存紧张的环境下,捕获此异常可以避免程序崩溃,并允许程序进行适当的错误处理或资源释放。
示例 2: 文件操作失败 (std::ios_base::failure)
文件操作(如打开文件、读取文件)时可能会失败,例如文件不存在或权限不足,这时会抛出 std::ios_base::failure 异常。这种异常需要捕获,以便提示用户或尝试其他操作。
1 |
|
需要捕获的原因:文件操作失败是常见的异常情况,捕获此异常可以使程序更具鲁棒性,允许进行错误恢复或友好提示。
示例 3: 自定义业务逻辑异常
有时,开发者会定义自定义异常来处理特定的业务逻辑错误,这些异常需要捕获以确保程序能够根据业务规则进行适当的处理。
1 |
|
需要捕获的原因:自定义业务异常通常代表业务逻辑中的特殊情况,捕获后可以根据业务需求采取相应的措施。
- 不需要捕获的异常
示例 1: 编程逻辑错误 (std::logic_error)
逻辑错误通常是程序中的缺陷或设计错误(例如非法访问容器元素),这些错误不应该通过捕获异常来处理,而是应该在开发过程中修复。
1 |
|
不需要捕获的原因:这种异常表示代码逻辑错误,应通过调试和修复代码来解决,而不是在运行时捕获。
示例 2: 类型转换错误 (std::bad_cast)
类型转换错误(例如 dynamic_cast 失败)通常表示设计上的问题,应该通过重构代码来避免,而不是捕获异常。
1 |
|
不需要捕获的原因:类型转换错误通常反映了设计问题,应通过代码改进来消除这些问题,而不是捕获异常。
3. 主函数中的通用异常捕获
在 main() 函数中,可以捕获所有未处理的异常,以确保程序在发生意外错误时能够进行必要的清理和友好退出。
1 | int main() { |
需要捕获的原因:在主函数中捕获所有异常,确保程序在发生未预料到的错误时能够优雅退出,避免资源泄漏或崩溃。
总结1
- 需要捕获的异常:包括可能在运行时发生且程序可以合理处理的异常,如内存分配失败、文件操作失败、自定义的业务逻辑异常等。
- 不需要捕获的异常:通常是反映程序设计或逻辑错误的异常(如逻辑错误、类型转换错误等),这些应通过代码修复而非运行时捕获来处理
总结2
需要抛出的异常:
- 严重的运行时错误:
- 内存分配失败 (
std::bad_alloc):系统内存不足时自动抛出,无法自行恢复,必须由调用者处理。 - 非法操作(如除零、无效参数):例如传递非法参数导致操作无法进行,抛出
std::invalid_argument通知调用者错误。
- 内存分配失败 (
- 不可恢复的逻辑错误:
- 违反前置条件或不变式:如违反程序预期的逻辑条件,抛出
std::logic_error以帮助发现代码中的问题。
- 违反前置条件或不变式:如违反程序预期的逻辑条件,抛出
不需要抛出的异常:
- 常规的可预测错误:
- 查找失败:如在容器中未找到元素,不应抛出异常,返回特殊值或使用
std::optional更合适。 - 文件打开失败:可以通过返回错误码或状态值来处理,而不是抛出异常。
- 查找失败:如在容器中未找到元素,不应抛出异常,返回特殊值或使用
- 可恢复的错误:
- 简单的用户输入错误:应通过提示用户重新输入,而非抛出异常。
- 抛出异常:用于处理严重、不可预测且程序无法自行恢复的错误。
- 不抛出异常:对于常规或可恢复的错误,使用返回值或其他非异常的手段来处理,以避免滥用异常机制。
Q2:编译期间异常和运行期间异常
- 编译期间异常
编译期间异常是指在编译阶段由编译器检测到的错误,通常这些错误会阻止代码的成功编译。常见的编译期间异常包括语法错误、类型不匹配、未定义的符号等。
示例 1: 语法错误
1 | int main() { |
解释: 在这个示例中,缺少分号 ;,这是一个语法错误。编译器会在编译期间报告这个错误,提示开发者修复。
示例 2: 类型不匹配
1 | int main() { |
解释: 这里的错误是试图将一个字符串字面量赋值给整型变量 x。编译器会在编译期间报告类型不匹配错误。
示例 3: 未定义的符号
1 | int main() { |
解释: 试图调用一个未定义的函数 undefinedFunction,编译器在编译期间会报告未定义符号的错误。
- 运行期间异常
运行期间异常是指程序在运行过程中发生的错误。这类异常在编译期间不会被检测到,而是在程序实际执行时才会发生。C++ 提供了异常处理机制 (try-catch) 来处理这些异常。
示例 1: 除零错误
1 |
|
解释: 在这个示例中,b 的值为 0,当试图执行 a / b 时,会导致除零错误。这种错误不会在编译期间被检测到,而是在程序运行时发生。
示例 2: 内存分配失败
1 |
|
解释: 在这个示例中,试图分配大量内存,可能会导致内存分配失败,从而抛出 std::bad_alloc 异常。这是一种运行时异常,需要通过 try-catch 块来捕获和处理。
示例 3: 越界访问
1 |
|
解释: 在这个示例中,试图访问超出 std::vector 边界的元素,会抛出 std::out_of_range 异常。这是一种运行时异常,需要通过 try-catch 块来捕获和处理。
总结
- 编译期间异常:是编译器在编译阶段检测到的错误,如语法错误、类型不匹配、未定义的符号等。这些错误必须在编译阶段修复,否则程序无法成功编译。
- 运行期间异常:是程序在运行过程中出现的错误,如除零错误、内存分配失败、越界访问等。这类异常通常需要使用异常处理机制 (
try-catch) 来捕获和处理,以防止程序崩溃。
Q3:C++17 optional关键字
可以使用optional处理异常,比如,如在容器中未找到元素,不应抛出异常,返回特殊值或使用 std::optional 更合适。
std::optional 是 C++17 引入的一个有用的工具,可以表示一个值可能存在或不存在的情况。它常用于返回类型,表示一个函数可能无法返回有效的值,而不是使用异常或特殊值(如 nullptr)来表示错误情况。
下面是一些 std::optional 的使用例子:
- 简单的函数返回值示例
假设我们有一个函数来查找一个整数数组中的某个元素,并返回该元素的索引。如果没有找到该元素,函数返回 std::nullopt。
1 |
|
输出:
1 | Found at index: 2 |
- 带默认值的
std::optional使用
假设我们想在没有找到值时返回一个默认值,可以使用 std::optional 的 value_or 方法。
1 |
|
输出:
1 | User Name: Guest |
- 检查
std::optional的存在性
可以用 has_value() 方法来检查 std::optional 是否包含值:
1 |
|
输出:
1 | Result: 5 |
可以通过自定义异常
1 |
|
Q4:try-catch放在for循环内和外的区别
try-catch放在for循环内
1 |
|
1 | Result: 1 |
try-catch放在for循环外
1 |
|
1 | Result: 1 |
适用场景总结:
- 如果希望在每次循环中处理异常且不影响后续迭代,选择循环内的
try-catch。 - 如果异常发生后不希望继续执行后续迭代,选择循环外的
try-catch。
以上是gpt的结论。
✳✳✳重点:
但是,本人在win和linux下分别测试,发现并不是这样的。
都是立即终止~
1 | penge@penge-virtual-machine ~/Desktop/test g++ mainn.cpp -o main -pthread -std=c++17 |
原因:C++ 不会自动抛出异常:不像 Java 这样的语言,C++ 不会自动为整数除零抛出一个异常。是因为cpp里面的异常没用除0异常!
Q5:C++ Exception 异常种类
C++ 中的异常类型丰富,主要包括以下几类:
基础异常类:std::exception。
内存分配相关异常:std::bad_alloc。
类型转换相关异常:std::bad_cast, std::bad_typeid。
逻辑错误异常:std::logic_error 及其子类(std::invalid_argument、std::out_of_range 等)。
运行时错误异常:std::runtime_error 及其子类(std::overflow_error、std::range_error 等)。
I/O 相关异常:std::ios_base::failure。
总结
std::optional用于表示可能有值,也可能没有值的情况。- 使用
std::nullopt表示std::optional中没有值。 value_or可以为std::optional提供一个默认值。has_value或直接在if语句中检查std::optional的值是否存在。
学习自:C++异常机制概述




