
HTTP学习笔记
时势造英雄,英雄亦造时势
好文收集
全局认识

HTTP
HTTP发展史
HTTP 协议始于三十年前蒂姆·伯纳斯 - 李的一篇论文;
论文中他确立了三项关键技术
- URI:即统一资源标识符,作为互联网上资源的唯一身份;
- HTML:即超文本标记语言,描述超文本文档;
- HTTP:即超文本传输协议,用来传输超文本;
HTTP/0.9 是个简单的文本协议,只能获取文本资源;
请求
1
GET /mypage.html
响应
1
2
3<html>
这是一个非常简单的 HTML 页面
</html>HTTP/1.0 确立了大部分现在使用的技术,但它不是正式标准;
- 增加了 HEAD、POST 等新方法;
- 增加了响应状态码,标记可能的错误原因;
- 引入了协议版本号概念;
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活;
- 传输的数据不再仅限于文本。
HTTP/1.1 是目前互联网上使用最广泛的协议,功能也非常完善;
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许响应数据分块(chunked),利于传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能。
HTTP/2 基于 Google 的 SPDY 协议,注重性能改善,但还未普及;
- 二进制协议,不再是纯文本;
- 可发起多个请求,废弃了 1.1 里的管道;
- 使用专用算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,“事实上”要求加密通信。
HTTP/3 基于 Google 的 QUIC 协议,是将来的发展方向。
简单说一下HTTP
(1)HTTP:超文本传输协议(HyperText Transfer Protocol),用于超文本传输,使用TCP。
(2)超文本:即超越了普通文本的文本,它是⽂字、图⽚、视频等的混合体,具备超链接,能从⼀个超⽂本跳转到另外⼀个超⽂本。
(3)HTML:超文本标记语言,是一种标识性的语言。HTML 文本是由 HTML 命令组成的描述性文本,是最常见的超文本。
(4)URL:HTTP使用统一资源定位符(URL)来标识与定位服务器上的资源,如常见的网址。
(5) 浏览器:浏览器(Web Broser),是检索、查看互联网上网页资源的应用程序,是使用 HTTP 协议的主要载体。
(6)HTTP 协议用于客户端和服务器之间的通信。用户在客户端使用浏览器,通过点击超链接或者输入URL来获取HTTP服务器上的资源,这些资源通过HTTP协议传送给客户端。
特点
- HTTP 是灵活可扩展的,可以任意添加头字段实现任意功能;
- HTTP 是可靠传输协议,基于 TCP/IP 协议“尽量”保证数据的送达;
- HTTP 是应用层协议,比 FTP、SSH 等更通用功能更多,能够传输任意数据;
- HTTP 使用了请求 - 应答模式,客户端主动发起请求,服务器被动回复请求;
- HTTP 是有连接无状态,顺序发包顺序收包,按照收发的顺序管理报文。
解释无状态
通俗解释
First,浏览器发了一个请求,说“我是小明,请给我 A 文件。”,服务器收到报文后就会检查一下权限,看小明确实可以访问 A 文件,于是把文件发回给浏览器。
Second,浏览器还想要 B 文件,由于无状态,服务器不会记录刚才的请求状态,不知道第二个请求和第一个请求是同一个浏览器发来的,所以浏览器必须还得重复一次自己的身份才行:“我是刚才的小明,请再给我 B 文件。
URI和URL的区别
(1) URI:统一资源标识符(uniform resource identifier),用来在Web上标识一个资源。Web上的可用资源,如HTML文档、图像、视频片段、程序等都是用URI来定位的。
(2) URL:统一资源定位符(uniform resource locator),它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何定位这个资源。URL一般由三部组成:
协议(或称为服务方式)
存有该资源的主机IP地址(有时也包括端口号)
主机资源的具体地址。如目录和文件名等。
补充:URN:Uniform Resource Name,统一资源名称。·
记住:
URL 一定是 URI
URL + URN 就是 URI
HTTP 报文和组成格式
(1) HTTP 报文主要由三大部分组成:
① 起始行(start line):描述请求或响应的基本信息;
② 头部字段(header):使用 key-value 形式更详细地说明报文;
③ 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
(2) 其中起始行和头部字段并称为请求头或者响应头,统称为 Header;消息正文也叫做实体,称为 body。
(3) HTTP 协议规定每次发送的报文必须要有 Header,但是可以没有 body,也就是说头部信息是必须的,实体信息可以没有。而且在 Header 和 body 之间必须要有一个空行(CRLF)。

(4) HTTP有两种报文:请求报文和响应报文
请求报文

1 | GET / HTTP/1.1 |
- GET / HTTP/1.1:这是请求行,表示客户端希望使用HTTP/1.1协议,通过GET方法获取服务器根目录(“/“)的资源。
- Host: www.baidu.com:这是请求头的一部分,指定了请求的目标服务器的主机名。
- Connection: keep-alive:这表示客户端希望服务器保持连接,以便后续请求可以复用这个连接。
- Cache-Control: max-age=0:这是告诉服务器,客户端不接受超过0秒的响应。【设置缓存用的】
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9:这表示客户端能接受的响应类型。
- Accept-Encoding: gzip, deflate, br:表示客户端可以接受的编码类型。
- Accept-Language: zh-CN,zh;q=0.9,en;q=0.8:表示客户端接受的语言类型。
- Cookie: BIDUPSID=8B0207CE0B6364E5934651E84F17999B; PSTM=1619707475:客户端存储的cookie信息。
补充:TCP Keepalive 和 HTTP Keep-Alive 是一个东西吗?
TCP Keepalive
- 当一个 TCP 连接在一段时间内没有任何数据传输时,TCP Keepalive 会定期发送一个小的探测包(Keepalive Probe)到对端。如果对端没有响应,则会重试几次。如果仍然没有响应,则认为连接已经断开,并通知应用程序。【查看连接是否断开没断】
HTTP Keep-Alive
- 可以使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答,避免了连接建立和释放的开销,这个方法称为 HTTP 长连接。【一次TCP连接发送多次HTTP信息】
响应报文

1 | HTTP/1.1 200 OK |
- Cache-Control: private:“private”表示缓存只能在客户端保存,是用户“私有”的,不能放在代理上与别人共享。而“public”的意思就是缓存完全开放,谁都可以存,谁都可以用。
常见的HTTP请求方法
必须是大写的形式
(1) HTTP请求方法是请求报文的请求行的第一个字段,决定此次请求的类型。
(2) HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
(3) HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。

GET, POST,PUT,DELETE
请求方法中的安全与幂等
安全:不会对服务器上的资源造成实质的修改。【GET和HEAD】
幂等:多次执行相同的操作,结果也都是相同的。
GET 和 HEAD 既是安全的也是幂等的,DELETE 可以多次删除同一个资源,效果都是“资源不存在”,所以也是幂等的。
Note:PUT是幂等,POST 不是。
POST 是“新增或提交数据”,多次提交数据会创建多个资源,所以不是幂等的;而 PUT 是“替换或更新数据”,多次更新一个资源,资源还是会第一次更新的状态,所以是幂等的。
常见的HTTP状态码
(1) 状态码由三位数字组成,第一个数字定义了响应的类别,共分五种类别:
① 1xx:指示信息 – 表示请求已接收,继续下一步处理
② 2xx:成功 – 表示请求已成功处理
③ 3xx:重定向 – 表示需要更改请求对象
④ 4xx:客户端错误 – 请求有错误
⑤ 5xx:服务器端错误 – 服务器未能实现合法的请求
(2) 下面来说一些比较常见的状态码
① 「100 Continue」:初始的请求已经接受,客户应当继续发送请求的其余部分
② 「200 OK」: 表示⼀切正常。
③ 「204 No Content」:也是常见的成功状态码,但响应头没有 body 数据。
④ 「206 Partial Content」:应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,⽽是其中的⼀部分,也是服务器处理成功的状态。
⑤ 「301 Moved Permanently」:表示永久重定向,说明资源不存在了,需⽤新的URL访问。
⑥ 「302 Found」:表示临时重定向,说明资源还在,但暂时要用另⼀个URL来访问。
⑦ 「304 Not Modified」:不具有跳转的含义,表示资源未修改,重定向已存在的缓冲⽂件,也称缓存重定向,⽤于缓存控制。
⑧ 「400 Bad Request」:表示客户端请求的报文有错误,但只是个笼统的错误。
⑨ 「401 Unauthorized」:该状态码表示发送的请求需要有认证信息
⑩ 「403 Forbidden」:表示服务器禁⽌访问资源,并不是客户端的请求出错。
⑪ 「404 Not Found」:表示请求的资源在服务器上不存在或未找到。
⑫ 「500 Internal Server Error」:与 400 类型,是个笼统通⽤的错误码,服务器发⽣了什么错误,我们并不知道。
⑬ 「501 Not Implemented」:表示客户端请求的功能还不⽀持,类似“即将开业,敬请期待”的意思。
⑭ 「502 Bad Gateway」:通常是服务器作为网关或代理时返回的错误码,表示服务器⾃身⼯作正常,访问后端服务器发⽣了错误。
⑮ 「503 Service Unavailable」:表示服务器当前很忙,暂时⽆法响应服务器,类似“⽹络服务正忙,请稍后重试”的意思。
HTTP长连接和短连接
(1) 在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次TCP连接,任务结束就中断TCP连接。
(2) 从HTTP/1.1起,默认使用长连接,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接。
头部字样:Connection: keep-alive
HTTP长连接在什么时候会超时?
HTTP一般会有httpd守护进程,里面可以设置keep-alive timeout,当tcp连接闲置超过这个时间就会关闭,也可以在HTTP的header里面设置超时时间。
TCP 的keep-alive包含三个参数,支持在系统内核的net.ipv4里面设置;当 TCP 连接之后,闲置了tcp_keepalive_time,则会发生侦测包,如果没有收到对方的ACK,那么会每隔 tcp_keepalive_intvl再发一次,直到发送了tcp_keepalive_probes,就会丢弃该连接。
转发和重定向
说说Cookie和Session
(1) Cookie:
① 由于HTTP是无状态的,服务器不会去记忆客户端的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担,能够把更多的 CPU 和内存⽤来对外提供服务。
② 但也因为无状态,服务器没有记忆能⼒,它在完成有关联性的操作时会⾮常麻烦。例如登录->添加购物⻋->下单->结算->⽀付,这些操作都要知道⽤户的身份才⾏。但服务器不知道这些请求是有关联的,每次都要问⼀遍身份信息。
③ 为了解决无状态引起的问题,引入了cookie机制。Cookie 是在客户端第⼀次请求后,服务器响应报文使用 Set-Cookie 字段发送“key=value”形式的 Cookie 值发送到用户浏览器并保存在本地的一小块数据。它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一客户端。为了保护 Cookie,还要给它设置有效期、作用域等属性,常用的有 Max-Age、Expires、Domain、HttpOnly 等;
④ Cookie的用途:会话状态管理、用户个性化设置、浏览器行为跟踪。
⑤ Cookie的缺点:每次请求都会需要携带Cookie 数据,因此会带来额外的性能开销。Cookie存放在本地浏览器,容易被篡改,不够安全。
(2) Session:
① Session和Cookie类似,都是用来存储用户信息。
② Session 存储在服务器端,通常存储在服务器上的文件、数据库或者内存中。
③ Session以键值对的方式进行存储,用户信息存储于Session,使用Session ID标识。
④ 在客户端登录完成之后,服务器会创建对应的session存储用户信息,然后把Session ID 发送给客户端进行保存。客户端后续访问服务器时会带着Session ID,服务器拿到 Session ID之后,则会在相应的数据中查找,如果找到对应的 session 就可以确认用户信息。
⑤ Session的缺点:所有用户的数据都存放在服务器,容易造成服务器压力过大。

Cookie和Session的区别
(1) 存储位置:Cookie存放在客户端,Session存放在服务端。
(2) 安全性:Cookie存放在客户端,容易被篡改,Session存储在服务端,数据比较安全。
(3) 存储类型:Cookie只能存放字符串,Session可存放各种数据类型。
(4) 空间限制:Cookie大小受限于浏览器,session大小受限于系统内存或者数据库大小。
Cookie和Session的适应场景
(1) Cookie只能存储字符串,Session则可以存储任何数据,因此在考虑数据复杂性时首选 Session。
(2) Cookie 存储在浏览器中,容易被恶意查看。Session存储在服务端,存储的数据比较安全。因此考虑数据安全性时首选Session。
(3) 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中,应该是两者混用。
谈谈代理
代理就是多了个中间人。
作用
- 健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用;
- 安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载;
- 加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本;
- 数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应;
- 内容缓存:暂存、复用服务器响应
代理服务器需要使用字段“Via”标记自己的身份,多个代理会形成一个列表;

如果想要知道客户端的真实 IP 地址,可以使用字段“X-Forwarded-For”和“X-Real-IP”。
URL长度限制
(1) 实际上HTTP协议没有对传输的数据大小进行限制,也没有对URL长度进行限制。
(2) 对 URL 限制的大多是浏览器和服务器。因为处理长URL要消耗比较多的资源,为了考虑性能和安全,两者会对URL长度加限制。
一个 TCP 连接中多个HTTP 请求可以同时发送吗
(1) HTTP1.0不支持。
(2) HTTP1.1可以发送多个HTTP请求,但无法做到同时发送与同时响应。
(3) HTTP2.0完全支持。
浏览器对同一域名建立的TCP 连接数的限制
(1) 有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
(2) 建立多个TCP连接的操作常发生在HTTP1.1,因为不支持多路复用,资源只能顺序加载,这样会导致用户体验不佳,因此常会多开几个TCP连接提升传输速度。
HTTP缓存问题
为方便大家理解,我们认为浏览器存在一个缓存数据库,用于存储缓存信息。
在客户端第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回后,将数据存储至缓存数据库中。
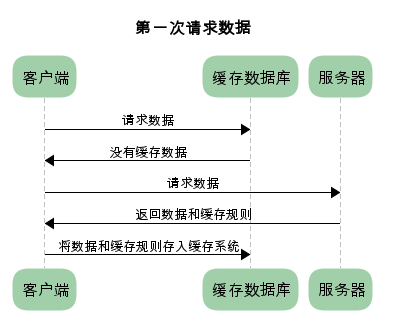
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类,我将其分为两大类(强制缓存,对比缓存)
在详细介绍这两种规则之前,先通过时序图的方式,让大家对这两种规则有个简单了解。
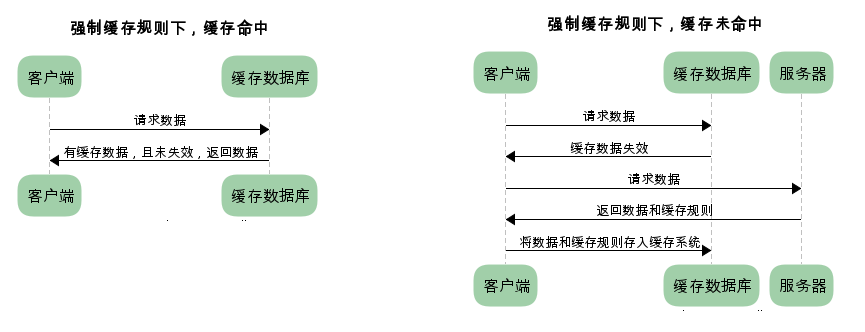
已存在缓存数据时,仅基于强制缓存,请求数据的流程如下
已存在缓存数据时,仅基于对比缓存,请求数据的流程如下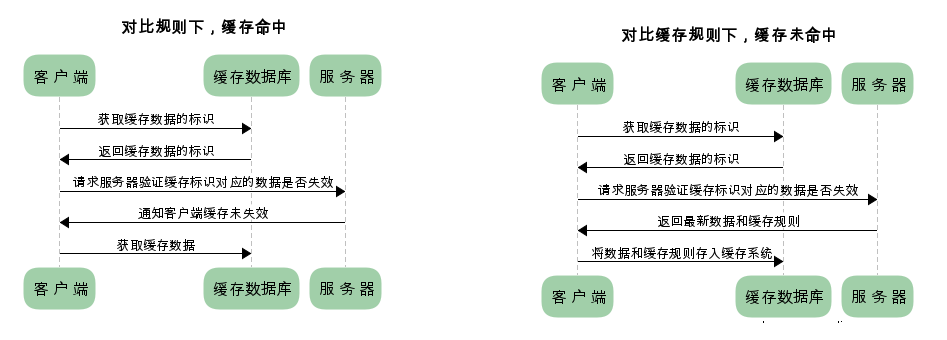
对缓存机制不太了解的同学可能会问,基于对比缓存的流程下,不管是否使用缓存,都需要向服务器发送请求,那么还用缓存干什么?
这个问题,我们暂且放下,后文在详细介绍每种缓存规则的时候,会带给大家答案。
我们可以看到两类缓存规则的不同,强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
HTTP断点续传
HTTP 1.1 协议支持断点续传,可以让客户端在上传或下载文件中断后,从上次中断的位置继续传输。这通过 HTTP 请求头中的 Range 和响应头中的 Content-Range 参数来实现。
客户端请求(使用 Range 请求头)
客户端在请求文件时,可以指定希望获取的文件部分内容。例如,如果客户端已经下载了文件的前 1000 个字节,希望从第 1001 个字节开始继续下载,则请求头中会包含:
1 | GET /path/to/file HTTP/1.1 |
这意味着客户端请求从文件的第 1000 个字节开始到文件末尾的部分。
服务器响应(使用 Content-Range 响应头)
服务器接收到请求后,如果支持断点续传功能,会响应部分内容,并在响应头中包含 Content-Range 参数。例如,如果文件总大小为 5000 字节,响应头会是:
1 | HTTP/1.1 206 Partial Content |
响应状态码 206 表示这是部分内容,Content-Range 头中包含当前传输的范围以及文件的总大小。这样客户端就可以从上次中断的位置继续下载文件。
示例
以下是一个完整的示例,假设文件总大小为 5000 字节。
第一次请求(从头开始下载)
客户端请求:
1 | GET /path/to/file HTTP/1.1 |
服务器响应:
1 | HTTP/1.1 200 OK |
第二次请求(从第 1000 个字节开始下载)
客户端请求:
1 | GET /path/to/file HTTP/1.1 |
服务器响应:
1 | HTTP/1.1 206 Partial Content |
在这个过程中,客户端通过 Range 请求头指定从第 1000 个字节开始下载,服务器通过 Content-Range 响应头告知客户端当前传输的字节范围和文件的总大小,并以 206 状态码表示部分内容传输成功。
通过这种机制,客户端可以在文件传输中断后继续下载,避免重复传输已经接收的数据,提高传输效率。
服务端推送
HTTP2.0的新特性
服务端推送(Server Push)是一种由 HTTP/2 协议引入的技术,可以让服务器在客户端请求之前主动将资源推送到客户端。这种机制可以显著提高页面加载速度,因为在页面渲染时,一些资源已经在客户端缓存中。
示例说明
假设有一个简单的网页 index.html,它依赖于 style.css 和 script.js 这两个资源。以下是一个示例展示如何使用 HTTP/2 服务端推送技术。
客户端请求
客户端请求 index.html:
1 | GET /index.html |
服务器响应并推送资源
服务器响应 index.html 并推送 style.css 和 script.js:
1 | 200 |
index.html 的内容:
1 |
|
同时,服务器还会推送 style.css 和 script.js:
推送 style.css:
实际应用
要在服务器上实现 HTTP/2 服务端推送,可以使用支持 HTTP/2 的 Web 服务器,例如 Nginx、Apache 或 Node.js 等。以 Nginx 为例:
Nginx 配置示例
在 Nginx 的配置文件中,可以使用 http2_push 指令来配置服务端推送:
1 | server { |
通过这样的配置,当客户端请求 index.html 时,Nginx 会自动将 style.css 和 script.js 文件推送到客户端。
HTTPS
SSL/TLS协议
Secure Sockets Layer
(1) HTTP 由于是明⽂传输,意味着在传输过程中的信息,对外部是完全可见的,因此技术人员可以很方便进行抓包读取数据,为我们调试⼯作带了极⼤的便利性。
(2) 明文传输所带来的缺陷就是不安全。在数据安全上存在以下三个⻛险:
① 使用明文进行通信,内容可能会被窃听;
② 不验证通信方的身份,通信方的身份有可能遭遇伪装;
③ 无法证明报文的完整性,报文有可能遭篡改。
(3) 为了解决这个问题,在HTTP 与 TCP 层之间加⼊了 SSL/TLS 协议。后面常将HTTP与SSL/TLS合并称为HTTPS。

(4) SSL:代表安全套接字层(Secure Sockets Layer)。它是一种用于加密和验证应用程序(如浏览器)和Web服务器之间传输的数据的一个特殊应用层。
(5) TLS:SSL层所用的协议(SSL 发展到 v3 将其改名为TLS,传输层安全,Transport Layer Security),是用来认证用户和服务,加密数据,维护数据的完整性的应用层协议。
补充1:OpenSSL:它是一个著名的开源密码学程序库和工具包,几乎支持所有公开的加密算法和协议。
HTTPS是什么
HTTPS 并不是新协议,而是让 HTTP 先和 SSL通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
加密是什么
加密就是对明文数据按某种特殊算法进行处理,使其成为不可读的一段代码,这段代码被称为“密文“。密文可以通过”密钥“解密,还原出原来的明文。通过这种方法可以保护数据,不被非法窃取和阅读。
密钥的类型
(1) 对称密钥:由一组相同的密钥对组成,加密和解密使用同一个密钥。

(2) 非对称密钥:由一组不同的密钥对组成,加密与解密必须使用不同的密钥,这两个密钥分别叫做公钥和私钥。公钥是可以公开给所有人的,而私钥需要自己保密的。使用公钥加密的数据只有使用私钥才能解开。使用私钥加密的数据只有使用公钥才能解开。

(3) 实际上私钥不是用来加密的,他是一种签名手段,准确的说法应该是 「私钥签名,公钥验签」,一般所说的非对称密钥指的是公钥加密,私钥解密。
利用密钥给数据加密
(1) 对称密钥加密:使用对称密钥来加密和解密数据【服务器和网站持有同一把钥匙】

① 优点:数据加密和解密的运算速度快
② 缺点:通信双方在交换密钥时必须明文通信,无法安全地将密钥传输给对方
(2) 非对称密钥加密:使用非对称密钥来加密和解密数据,用公钥进行加密,再用密钥进行解密。
【服务器原先持有公钥和私钥,现在将公钥给你,然后你用公钥加密发给服务器,服务器再用私钥解开你发的内容】

① 优点:由于公钥的公开性,可以安全地将密钥传输给对方。
② 缺点:数据加密和解密的运算速度慢。
(3) 非对称加密和非对称加密都有一个共同缺点,它们只能保证通信的内容不会泄漏,即“防窃听”,却没能解决“伪装”和“篡改”,不能保证通信方的身份有效性。
HTTPS采用的是对称密钥加密还是非对称密钥加密?
HTTPS采用了混合加密,这种加密方式结合了对称密钥加密和非对称密钥加密各自的优点,保证安全性的前提下让加密解密速度变快。
(1) 首先使用一组非对称密钥来加密传输一组对称密钥,来保证传输过程的安全性。
(2) 通信双方再使用对称密钥来加密通信过程中的数据,来保证通信过程的效率。【由算法决定的】
(3) 混合加密只保证“防窃听”,想解决“伪装”和“篡改”需使用“签名”与“数字签名”。
- Client发起请求(端口443)【Server中有公钥和私钥,只发送公钥】
- Server返回公钥证书给Client
- Client验证证书
- Client生成对称密钥,用公钥加密后发给Server
- Server使用私钥解密,得到对称密钥
- C/S双方使用对称密钥:
- 加密明文并发送
- 解密密文得到明文
通俗理解:
(1) 采用非对称密钥确保传输过程的安全性
解释:
- 非对称加密使用一对密钥:公钥和私钥。公钥可以公开给任何人,而私钥必须保密。
- 在通信开始时,双方使用非对称加密对称密钥,以确保在传输过程中对称密钥的安全。
举例:
- 假设小明(发送方)和小红(接收方)要进行安全通信。
- 小红生成一对非对称密钥:公钥和私钥,并把公钥发送给小明。
- 小明使用小红的公钥加密一个对称密钥,然后将加密后的对称密钥发送给小红。
- 小红收到后,使用自己的私钥解密,获得对称密钥。
(2) 采用对称密钥确保通信过程的效率
解释:
- 对称加密使用一个单一的密钥进行加密和解密,速度快,适合大量数据的加密。
举例:
- 当小红解密并获得对称密钥后,小明和小红使用这个对称密钥加密和解密他们之间的通信数据。
- 这样一来,双方的通信数据在传输过程中是加密的,防止被窃听,同时加密和解密的速度很快,保证通信的效率。
总结
- 安全性:使用非对称密钥加密对称密钥,确保在传输过程中的安全。
- 效率:使用对称密钥加密通信数据,确保通信过程的效率
签名
(1) 签名是一种身份认证机制,它保证了每一个通信方都拥有自己的专属标签,其他人难以伪造,而且其他人能够验证这个标签,确认它确实属于某一个通信方。
(2) 签名机制的实现可以用非对称密钥解决,我们可以用私钥进行签名,再用公钥进行验签。
(3) 在通信之前,发送方利用私钥对通信内容加密生成签名,将签名连同通信内容一同发送,对方可利用公钥解密该签名,确保签名的正确性。
(4) 由于私钥的保密性,其他人无法伪装。又由于公钥的公开性,任何一个人都可以通过公钥解开私钥加密的数据来进行身份验证。

缺点
签名是利用非对称密钥的加密解密来实现的,而非对称密钥的加密解密依赖于复杂的数学运算,当数据量大的时候,计算签名会非常耗时。为了解决这一问题,引入了摘要和数字签名。
摘要
(1) 一段信息,经过摘要算法处理而得到的一串定长的哈希值,就是摘要(dijest)。
(2) 信息可以是任意长度,而摘要是定长,摘要算法将无限长的数据映射成有限长的数据。
(3) 摘要是不可逆转的,它不存在解密,从摘要反推原信息也很难。
(4) 原数据如果发生变化,那么计算出来的摘要也会发生变化。如果两个数据算出来的摘要是一样的,说明两个数据是完全相同。
数字签名
(1) 数字签名需要先对通信数据生成摘要,再对摘要进行签名运算,得到的签名即数字签名。
(2) 在通信时,发送方先生成数字签名,将数字签名连同通信内容一同发送,对方可利用公钥解密该数字签名,得到一段摘要。(如果公钥解密失败,说明对方身份被“伪装”)
(3) 第二步则对通信内容使用摘要算法生成摘要(前提是摘要算法公开),与上一段摘要进行比对看是否一致,可验证内容是否被“篡改”。

【可以理解:就是对原来的文件进行类似md5算法得到一串字符串后用私钥签名,将前面后的文件和签名发给对方,对方用公钥获取md5算法,与原文信息(自己进行运算)一遍,查看是否相等】
再补充:
- 摘要的含义:摘要是通过特定的哈希算法(如SHA-256)对原始数据进行计算得到的一串固定长度的字符串。
- 签名的含义:数字签名是对摘要进行加密运算得到的一串数据,通常使用发送方的私钥进行加密。
数字签名和签名的不同
(1) 签名:直接对通信数据利用私钥生成签名。
(2) 数字签名:先对通信数据生成摘要,再对摘要利用私钥生成签名。
利用混合加密和数字签名是否充分保证了通信安全
(1) 利用混合加密,我们可以对数据进行加密传输,具备“防窃听”。
(2) 利用数字签名,我们可以验证对方身份和比对数据完整性,具备“防篡改”和“防伪装”。
(3) 混合加密和数字签名他们都利用了非对称密钥加密技术,那么就必须保证一个前提:某个通信方的公钥能够通过网络安全地传输给对方,而不会被其他人篡改或伪装。
(4) 如下所示,在传输公钥这一步没能做到“防篡改”和“防伪装”,导致后续的通信均失败。

(5) 上面提到,数字签名可以保证“防篡改”和“仿伪装”,但数字签名前提是安全地把公钥传输给对方,这就导致了死锁,为了解决这个问题,我们引入了“数字证书”和第三方机构“CA”。
CA是什么
数字证书认证机构(CA,Certificate Authority),是客户端与服务器双方都可信赖的第三方机构,它具备颁布“数字证书”的职能。
数字证书是什么
(1) 数字证书是一个标志通信方身份信息的数字认证,人们可以在网上用它来识别对方身份。
(2) 数字证书的制作流程:某一个通信方向“CA”提出证书申请,“CA”会将证书的颁布机构、证书有效期、证书持有者的公钥、证书持有者身份等信息用“CA”的私钥进行签名运算,生成签名。之后再将签名和这些信息存放在一起,这就是“数字证书”。
(3) 数字证书的使用流程:某一个通信方向“CA”申请一个数字证书,然后将该证书发送给通信对象,对方获取证书后利用“CA”的公钥进行验签,验证通过即可证明对方身份,并且获取对方的公钥,之后就可以利用对方公钥来进行混合加密和数字签名,确保接下来通信过程的安全。
简单来说,计算机中没有什么东西是加一层不能解决的,如果不能解决,就加2层。
数字证书的可靠性保证
数字证书需要由“CA”颁布,为了证明“CA”是合法的且其数字证书是可靠的,在各个“CA”之间设立了层级关系,下层“CA”的数字证书是需要上层“CA”签名的,而最上层的根“CA”的数字证书(根证书)是自签的,根证书由操作系统和浏览器预装在计算机内部的。
数字签名和数字证书的区别
(1) 数字证书本身就包含了数字签名,数字证书将一些重要数据和对应的数字签名进行打包。
(2) 数字签名可由任何一方制作,数字证书只能由CA颁布。
数字证书的使用过程中,CA的公钥能否被伪造
(1) 大部分主机内部都预先安装了根证书,里面记录了可信赖的CA机构信息及其公钥。
(2) 即使根证书无法使用,接受方也可进行网上查询对比,判断CA公钥的真实性。
说说HTTPS的通信过程
(1) HTTPS使用了混合加密+数字签名+数字证书的机制。
(2) 混合加密:在通信正式开始前,先使用一组非对称密钥来加密传输一组对称密钥,这样双方就获得了一组相同的对称密钥,之后的通信过程都使用对称密钥来加密传输数据,确保数据的机密性,实现“防窃听”,同时还具有较高的加密解密效率。【防止被中间人看到】
(3) 数字签名:在通信时,先对通信数据生成数字签名,发送数据时连同数字签名一同发送。对方可利用公钥验证该数字签名,得到一段摘要。之后对方也可以对通信内容使用摘要算法生成摘要,对比上一步验签得到的摘要,看是否相同,通过这一步可以实现“防伪装”和“防篡改”。【防止信息和发之前的不一样】
(4) 数字证书:为了确保公钥安全性,先由某一通信方向“CA”申请数字证书,通信方获得数字证书后发送给通信对象,对方获取证书后利用“CA”的公钥进行验签,验证通过即可证明对方身份,并且获取对方的公钥,之后的通信就可以利用该公钥完成“混合加密”和“数字签名”【防止是对方发的】
HTTPS和HTTP的区别
(1) HTTPS采用了混合加密+数字签名+数字证书,安全性更高。
(2) HTTPS协议需要到“CA”申请数字证书,一般免费证书较少,因而需要一定费用。
(3) HTTP和HTTPS使用的端口不一样,前者是80,后者是443。
HTTP各版本的特点
(1) HTTP1.0:
① 简单、快速、灵活
② 短连接:短连接的含义是限制每次连接只处理一个请求。服务器处理完客户的一次请求后就会断开连接,这种方式比较简单,能节省服务器的资源消耗。
③ 无状态:无状态是指协议对于事务处理没有记忆能力,客户端发送HTTP请求后,服务器根据请求响应数据,但它不会记录客户端的信息,无法判断某次请求与上一次请求是否来自同一客户端。
(2) HTTP1.1:
① 长连接:默认持久连接,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接,可以发送多次HTTP请求 。
② 管线化:客户端可以发出多个HTTP请求,只要前一个请求发送出去之后就可以继续发送第二个请求【队头阻塞可能就在这个只要前一个请求发送出去上】,而不用一个个等待响应之后再发送,但是服务器同一时间只能处理一个HTTP请求,后续到达的HTTP请求需要排队等待。
③ 断点续传:就是可以将一个大数据,分段传输,客户端可以慢慢显示。
(3) HTTP2.0:
① 二进制编码:HTTP2.0采用二进制格式而非文本格式。
② 多路复用:HTTP2.0是完全多路复用的,客户端可以同时发送多个HTTP请求,服务器也可以同时进行处理,不用进行排队。【每个请求和响应都有独立的流 ID,彼此不会阻塞】
③ 报头压缩:HTTP2.0使用报头压缩,降低了头部开销。
④ 推送缓存:服务端可以在发送页面HTML时主动推送其它资源,而不用等到浏览器解析到相应位置,发起请求再响应。

参考资料:
面试题:
Q1:.发了一个动态图片的朋友圈需要关注http的哪些指标
在发布一个包含动态图片的朋友圈时,需要关注以下几个关键的 HTTP 指标,以确保用户体验良好,并且服务器能够高效处理请求:
- 响应时间(Response Time)
定义:从客户端发送请求到接收到完整响应的时间。
关注点:确保响应时间尽可能短,以提供流畅的用户体验。
- 吞吐量(Throughput)
定义:单位时间内服务器处理的请求数量。
关注点:确保服务器能够处理大量并发请求,尤其是在高峰时段。
- 错误率(Error Rate)
定义:请求失败的比例,通常以 HTTP 状态码表示(如 4xx 和 5xx)。
关注点:监控和减少错误率,确保服务稳定。
- 延迟(Latency)
定义:请求从客户端到服务器再返回客户端的总时间,包括网络传输时间。
关注点:优化网络路径和减少数据包丢失,以降低延迟。
- 请求大小(Request Size)
定义:客户端发送的请求数据的大小。
关注点:确保请求大小合理,避免过大导致网络拥塞或服务器负载过高。
- 响应大小(Response Size)
定义:服务器返回的响应数据的大小。
关注点:优化图片压缩和格式选择,减少响应大小,加快加载速度。
- 并发连接数(Concurrent Connections)
定义:同时与服务器保持连接的客户端数量。
关注点:确保服务器能够处理高并发连接,避免连接超时或拒绝服务。
- 缓存命中率(Cache Hit Rate)
定义:缓存中找到并返回的请求比例。
关注点:提高缓存命中率,减少服务器负载和响应时间。
- DNS 解析时间(DNS Resolution Time)
定义:将域名解析为 IP 地址所需的时间。
关注点:优化 DNS 解析时间,减少用户等待时间。
- SSL/TLS 握手时间(SSL/TLS Handshake Time)
定义:建立安全连接所需的时间。
关注点:优化 SSL/TLS 握手过程,减少安全连接的延迟。
- 服务器处理时间(Server Processing Time)
定义:服务器处理请求并生成响应的时间。
关注点:优化服务器代码和数据库查询,减少处理时间。
- 网络传输时间(Network Transfer Time)
定义:数据在网络中传输的时间。
关注点:优化网络路径和带宽,减少传输时间。





